MID2BMSON
MIDIをBMSON図表に変換する凄いやつ。
BMSONの"mode"keyboard-24k-double""keys"beat-7k"
いまのところ生成された"y".0”
引っ張ってきた音階の情報を各notesに非標準propertyとして埋め込む手もあるかも。たとえばMIDI上で音階がC4として設定されているnoteなら、"note"x"
MID2BMSON公開から一時間くらいでたれこんでくださった方、ありがとうございました!
MIDIをBMSON図表に変換する凄いやつ。
BMSONの"mode"keyboard-24k-double""keys"beat-7k"
いまのところ生成された"y".0”
引っ張ってきた音階の情報を各notesに非標準propertyとして埋め込む手もあるかも。たとえばMIDI上で音階がC4として設定されているnoteなら、"note"x"
MID2BMSON公開から一時間くらいでたれこんでくださった方、ありがとうございました!
書きかけscriptに
Electron製のBMS install manager。
bndlrを起動すると、
個人でmeta情報を整備したい場合は、いまのところbms-bundle-manifest-jsを利用するとよいようだ。これはnpmがNode.jsのpackage managerであることを理解できるuser向けだろうから、よくわかっていない私は近日中に公開される予定のonline validatorを待って、実際にJSONを書いてみるつもり。
(素早くたれこんでくださった匿名さん、ありがとうございました!)
先日の愚鈍な文字列操作を数値操作に置き換えて100000回実行してみた。
var Bitwise = function () {};
Bitwise.prototype.p = (function () {
var a = [];
var i = 0;
while (i < 33) {
a.push(Math.pow(2, i)); // 2 ** i
i += 1;
}
return a;
}());
Bitwise.prototype.toInt32 = function (x) {
var n = Number(x);
var neg;
if (!isFinite(n) || n === 0) { // for IE
//if (!Number.isFinite(n) || n === 0) {
return 0;
}
if (n < 0) {
neg = true;
n = -n;
}
n = Math.floor(n) % this.p[32];
if (n > this.p[31]) {
n -= this.p[32];
}
return (
neg
? -n
: n
);
};
Bitwise.prototype.toUint32 = function (x) {
var n = Number(x);
var neg;
if (!isFinite(n) || n === 0) { // for IE
//if (!Number.isFinite(n) || n === 0) {
return 0;
}
if (n < 0) {
neg = true;
n = -n;
}
n = Math.floor(n);
if (neg) {
n = -n;
}
n = n % this.p[32];
return (
(n < 0)
? this.p[32] + n
: n
);
};
Bitwise.prototype.toBinary = function (int32) {
var a = [];
var i = 0;
var p = int32;
var neg;
var carry;
if (p < 0) {
neg = true;
p = -p;
}
while (p >= 2) {
a[i] = p % 2;
i += 1;
p = Math.floor(p * 0.5);
}
a[i] = p;
i += 1;
while (i < 32) {
a[i] = 0;
i += 1;
}
if (!neg) {
return a;
}
i = 0;
while (i < 32) {
a[i] = Number(!a[i]);
i += 1;
}
a[32] = 0;
i = 0;
do {
carry = a[i];
a[i] = Number(!a[i]);
i += 1;
} while (carry);
a.pop();
return a;
};
Bitwise.prototype.not = function (num) {
var a = this.toBinary(this.toInt32(num));
var i = 32;
var n = 0;
var p = this.p;
while (i) {
i -= 1;
n += p[i] * (!a[i]);
}
return this.toInt32(n);
};
Bitwise.prototype.and = function (l, r) {
var L = this.toBinary(this.toInt32(l));
var R = this.toBinary(this.toInt32(r));
var p = this.p;
var i = 32;
var n = 0;
while (i) {
i -= 1;
n += p[i] * (L[i] && R[i]);
}
return this.toInt32(n);
};
Bitwise.prototype.or = function (l, r) {
var L = this.toBinary(this.toInt32(l));
var R = this.toBinary(this.toInt32(r));
var p = this.p;
var i = 32;
var n = 0;
while (i) {
i -= 1;
n += p[i] * (L[i] || R[i]);
}
return this.toInt32(n);
};
Bitwise.prototype.xor = function (l, r) {
var L = this.toBinary(this.toInt32(l));
var R = this.toBinary(this.toInt32(r));
var p = this.p;
var i = 32;
var n = 0;
while (i) {
i -= 1;
n += p[i] * (L[i] !== R[i]);
}
return this.toInt32(n);
};
Bitwise.prototype.leftShift = function (l, r) {
var L = this.toBinary(this.toInt32(l));
var R = this.and(this.toUint32(r), 31);
var p = this.p;
var n = 0;
var i = 0;
var B = [];
// L = new Array(R).fill(0).concat(L).slice(0, 32);
while (i < R) {
B[i] = 0;
i += 1;
}
while (i < 32) {
B[i] = L[i - R];
i += 1;
}
while (i) {
i -= 1;
n += p[i] * B[i];
}
return this.toInt32(n);
};
Bitwise.prototype.rightShift = function (l, r) {
var L = this.toBinary(this.toInt32(l));
var R = this.and(this.toUint32(r), 31);
var p = this.p;
var n = 0;
// L = L.concat(new Array(R).fill(L[31])).slice(-32);
var B = [];
var padd = L[31];
var i = R;
while (i < 32) {
B[i - R] = L[i];
i += 1;
}
i = B.length;
while (i < 32) {
B[i] = padd;
i += 1;
}
while (i) {
i -= 1;
n += p[i] * B[i];
}
return this.toInt32(n);
};
Bitwise.prototype.unsignedRightShift = function (l, r) {
var L = this.toBinary(this.toUint32(l));
var R = this.and(this.toUint32(r), 31);
var p = this.p;
var n = 0;
// L = L.concat(new Array(R).fill(0)).slice(-32);
var B = [];
var i = R;
while (i < 32) {
B[i - R] = L[i];
i += 1;
}
i = B.length;
while (i < 32) {
B[i] = 0;
i += 1;
}
while (i) {
i -= 1;
n += p[i] * B[i];
}
return this.toUint32(n);
};
if (typeof Object.create !== "function") {
Object.create = function (proto) {
var F = function () {};
F.prototype = proto;
return new F();
};
}
var Random = function (seed) {
this.x = 123456789;
this.y = 362436069;
this.z = 521288629;
this.w = seed || 88675123;
};
//Object.assign(Random.prototype, Bitwise);
Random.prototype = Object.create(Bitwise.prototype);
Random.prototype.next = function () { // Xorshift128
var t = this.xor(this.x, this.leftShift(this.x, 11));
this.x = this.y;
this.y = this.z;
this.z = this.w;
this.w = this.xor(
this.xor(this.w, this.unsignedRightShift(this.w, 19)),
this.xor(t, this.unsignedRightShift(t, 8))
);
return this.w;
};
Random.prototype.nextInt = function (min, max) { // from min to max
return min + (Math.abs(this.next()) % (max + 1 - min));
};Bitwise classは元々ただのobjectをObjectObject
元の愚鈍な文字列操作版からは2.5倍から8倍ほど高速化することができたが、
| Browser | Elapsed |
|---|---|
| Vivaldi 3.7.2218.52 | 447 ms |
| Firefox 87 | 1653 ms |
| Internet Explorer 6.0.2800.1106 | 57843 ms |
vs.
| Browser | Elapsed |
|---|---|
| Vivaldi 3.7.2218.52 | 8 ms |
| Firefox 87 | 7 ms |
| Internet Explorer 6.0.2800.1106 | 547 ms |
試す前から結論は明らかだったが、
どこで使うのかわからなかったmethodを私は奇跡的に思い出すことができた。
Random.prototype.next = function () { // Xorshift128
this.x[4] = this.x[0] ^ (this.x[0] << 11);
// this.x[0] = this.x[1];
// this.x[1] = this.x[2];
// this.x[2] = this.x[3];
this.x.copyWithin(0, 1, 4);Bitwise Shift演算子っぽい動きは、このmethodを使えばだいぶ短く書けそう。
XorshiftのJavatoInt32かtoUint32が挟まるので遅かったらしい)、現代の実行環境は問題なく最適化してくれるようだ(あるいはTyped
const Random = function (seed = 88675123) {
this.x = Uint32Array.of(123456789, 362436069, 521288629, seed, 0);
};
Random.prototype.next = function () { // Xorshift128
this.x[4] = this.x[0] ^ (this.x[0] << 11);
this.x.copyWithin(0, 1, 4);
this.x[3] = (this.x[3] ^ (this.x[3] >>> 19)) ^ (this.x[4] ^ (this.x[4] >>> 8));
return this.x[3];
};
Random.prototype.nextInt = function (min, max) { // from min to max
return min + (Math.abs(this.next()) % (max + 1 - min));
};Xorshift128、0にするのは厳禁」だが、それ以外なら何でもいいらしい。そこは変更する理由はないのでseedはそのままにした。計算途中の一時的な値もTypedtoInt32が適用されてしまうらしいので、元の一時変数tはTyped
TypedArray版の実行結果はNumber版とは微妙に異なる(C言語版と同じ結果になると思われる)。どちらも2進数表現としては等価だが、
const random = new Random(); // seed: default parameters (= 88675123)
random.next(); // 0b11011100101000110100010111101010 // -593279510 or 3701687786
random.next(); // 0b00011011010100010001011011100110 // 458299110
random.next(); // 0b10010101000100000100100110101010 // -1794094678 or 2500872618
random.next(); // 0b11011000100011010000000010110000 // -661847888 or 3633119408
random.next(); // 0b00011110110001111000001001011110 // 516391518
random.next(); // 0b10001101101100100100000101000110 // -1917697722 or 2377269574
random.next(); // 0b10011010111110000001010001000011 // -1695017917 or 2599949379
random.next(); // 0b00101010110000000000111100101100 // 717229868
random.next(); // 0b00001000001101111010110101011000 // 137866584
random.next(); // 0b00010111100100000110010101101001 // 395339113このようにNumber版には負数が混じるため、絶対値を得るnextInt
// random.nextInt(1, 1024) x 30:
// Number: [535, 743, 599, 849, 607, 699, 958, 813, 345, 362, 469, 550, 273, 746, 653, 812, 53, 535, 333, 903, 169, 1013, 173, 601, 866, 922, 606, 737, 795, 916, 358]
// TypedArray: [491, 743, 427, 177, 607, 327, 68, 813, 345, 362, 469, 550, 753, 746, 373, 214, 53, 535, 333, 903, 169, 13, 173, 425, 160, 922, 606, 737, 795, 916, 358]確率分布としてはどちらも大差なさそうに見えるが、よくわからない。#RANDOM 1024、ただし対応する枝は#IF 16まで」みたいな場合は困るかも。いや、剰余を使うならべつに問題ないんじゃないかな…… ん〜〜まあ無難にC言語版に寄せておくか。
Linterがbitwise演算子に目くじらを立てるので、私は「XorもShiftも使わないXorshift」も書いてみた。"0""1"
bitwise.not(-1234567.89); // 1234566
bitwise.and(-1234, -567.89); // -1784
bitwise.or(-1234, -567.89); // -17
bitwise.xor(-1234, -567.89); // 1767
bitwise.leftShift(-1234, -567.89); // -631808
bitwise.rightShift(-1234, -567.89); // -3
bitwise.unsignedRightShift(-1234, -567.89); // 8388605文字列を使わず数値型のままbitmaskとやらを行えば、たぶん10倍以上高速化できそうな気がするが、実用性が皆無とわかりきっているもどきにこれ以上手を入れるのはさすがに不毛かな〜
Linterがbitwise演算子を戒める理由は、論理演算子の書き間違いに見えるかららしい。未来の私は~~-567.89や-567.89|0
私の書きかけscriptは、
JSON<!DOCTYPE html>
<meta charset="utf-8">
<title>JSON nest3104</title>
<style>
pre {
inline-size: 100%;
white-space: pre-wrap;
}
</style>
<body>
<h1>JSON nest3104</h1>
<pre id="TEST"></pre>
<script>
var getProperty = function (object, propertyPath) {
// https://qiita.com/standard-software/items/bb044217d0a4b394b8e2
if (!object) {
return undefined;
}
var result = object;
var propertyArray = propertyPath.slice(1, -1).split("][");
var i = 0;
var l = propertyArray.length;
var property;
var quot = "\"";
while (i < l) {
property = propertyArray[i];
if (
property.length > 2
&& property.charAt(0) === quot
&& property.slice(-1) === quot
) {
property = property.slice(1, -1);
}
// bracket記法なら空文字列は妥当なkeyのはずなのでcommented out
// if (property === "") {
// return undefined;
// }
if (typeof result[property] === "undefined") {
return undefined;
}
result = result[property];
i += 1;
}
return result;
};
(function () {
"use strict";
var maxlevel = 3104;
var rxCancel = new RegExp(new Array(100 + 1).join(" "), "g");
var p1 = "{\"type\":\"div\",\"attr\":{\"depth\":";
var p2 = "},\"children\":[";
var p3 = "]}";
var c = "[\"children\"][0]";
var json;
var result = [];
var q = [];
var query;
var i = 0;
var l = maxlevel / 2;
while (i < l) {
result.push(p1 + (1 + i * 2) + p2);
q.push(c);
i += 1;
}
q.pop();
while (i) {
result.push(p3);
i -= 1;
}
json = JSON.parse(result.join(""));
query = q.join("") + "[\"attr\"][\"depth\"]";
document.getElementById("TEST").appendChild(
document.createTextNode(
String("")
// + JSON.stringify(json, null, 1).replace(rxCancel, "")
+ "\n\njson" + query + ": \n"
+ JSON.stringify(getProperty(json, query), null, 1)
)
);
}());
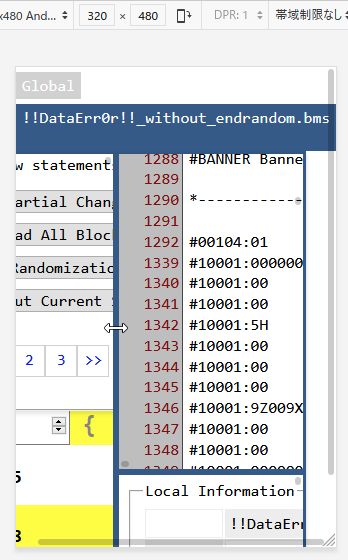
</script>一個目のJSON30000000層までは実際にpropertyにaccessできることを確認した。
一個目のJSON3105層以上で停止し、5017層以上で停止した。非再帰版JSON parserを自前で実装すれば、この問題は解決できそうだが、巨大なJSONに立ち向かうためにはそもそもjqのような入出力streamが必要なのかも。一応Streams APIとか既にあるし、
 ほぼ
ほぼ
まあ淡々と試行錯誤するのみ。
書きかけのcodeを忘れきる前に続きに取り掛かれたのでよかった。
BmsToAviがRandom seedを受け付けるsoftwareだった。
2000. 2. 3 AM 1:38
Ver 0.00a9
ランダムローディング時の乱数列の初期化値を与えられるようにした
0が本当にランダム それ以外は設定とみなす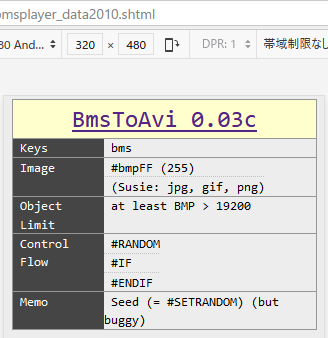 私は少なくとも2010年時点では「乱数列の初期化値」を
私は少なくとも2010年時点では「乱数列の初期化値」を#SETRANDOMと勘違いしており、この勘違いは十年以上もの間、正されなかった。な〜にが
情報系のliteracyが皆無な私はともかく、二十一世紀の義務教育課程を経た方々なら乱数のseed値という概念は普通に理解できそう(“65535”
Java#RANDOMやRANDOM optionの結果が常に一定になる)。生成器なら再現性はあったほうが便利かもしれない、なるほどな〜、と感じ入ったので真似させていただく予定。
いまのところ細かい不具合が多いように見えるが、どれも致命的ではなさそう。気になる方はOffline版を手元で各自修正すると良さそう。最後のoutput関数からjQueryを外せば一応動作する。あとはHTMLのtype="text" type="number"type="number"
XTRM Runtimeの詳細をどこかにmemoしていないか検索した際、
肝心のツクールはWAV slicing
μBMSCが特定の音声を再生しようとすると強制終了するらしいということを小耳に挟んだ。教えてくださった方、ありがとうございます。いまのところ心当たりはないが気をつけてみます。
Visual Basic 6.0 IDE サポート終了後に実施された2012年・
2016年の累積的なセキュリティ更新に対応しており、フリーソフトとしては現在安全に利用できる唯一のランタイムパッケージです。
同梱文書の通り、このprogramをinstallすれば手軽に最新のVB6動作環境が得られる。
BMSChecker作者です。
BMSChecker v
1 .2 .0で "「重複定義による音量調整」の検出が出来なくなった" 件について、これに該当する機能に心当たりが無いのですが、以前はどのように利用されていたのでしょうか。
はじめまして。そしてごめんなさい、件の機能は私の勘違いでした。たとえば#041以降で「重複定義による音量調整」を行っていますが(各小節BGMの16–17列目)、
「こんなところまで検出してくれるなんて凄いな〜」と感心した記憶がはっきり残っているのがおそろしい…… 私は自分の経験をまったく信じられない……
#ENSDWに対応したbms-language-supportですが、
VScodeの構文解析が基本RegExpなので、閉じタグがない状態をうまく記載する方法が思いつかなくて…
(釈迦の耳に説法でしょうけれど)#IF–#ELSEIF–#ELSE)–#ENDIFのSyntax highlightingは期待通りに働いているように見えるので、これをほぼそのまま転用できるのではないでしょうか?
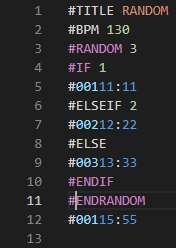
#TITLE SWITCH
#BPM 130
#SWITCH 3
#CASE 1
#00111:11
#CASE 2
#00212:22
#SKIP
#DEF
#00313:33
#ENDSW
#00115:55#IFを#SWITCHに置き換える。#ELSEIFを#CASEに置き換える。#ELSEを#DEFに置き換える。#ENDIFを#ENDSWに置き換える。この場合に問題となりそうなのは、#SWITCHから最初のlabelまでの間のnode・#SWITCHのscopeにあるが#SWITCH blockの直下にない#SKIP・他の#CASE labelsよりも上に書かれた#DEF、の取り扱いでしょうか。そのあたりまで正規表現だけでどうにかできるのか私には分かりませんが、他の言語のrulesetも正規表現で書かれているなら参考にはできそう。あと先日の当日記のBMS例に閉じtagがなかったのは私の書きかけparserが緩いだけであって、真っ当なvalidatorなら赤く染めるのが正しそうです。
#TITLE else first
#BPM 130
#RANDOM 3
#ELSE
#00313:33
#IF 1
#00111:11
#ELSEIF 2
#00212:22
#ENDIF
#ENDRANDOM
#00115:55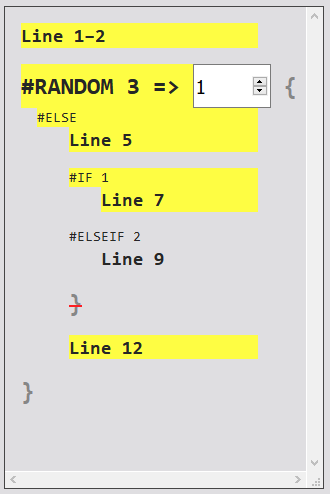
入れ子あり・かつ終端符を補う拙作parserだとこうなるのもわかるけど、とはいえこれを見ていると「突然の#ELSE」を無条件で丸吞みするのはヤバなのでは……って思えてくる。#ELSEは必ず選ばれ、あとは二択になる。Codeの動きがわからない。まあ「突然の#DEF」ならともかく、#ELSE」がどう解釈されても図表著者はどうこういえない。
[追記] Codeの動きがたぶん分かった。#ELSEIFをsupportしていないので、#ELSEIF 2はただの#ELSEとして解釈される、っぽい。
#TITLE void
#BPM 130
#SWITCH 1
#00111:11
#ENDSWIIDXvはこういうのをきちんと叱ってくれるので良い。
NOTICE: Notes without keysound exist: 100.0%
などと知らせてくれるようになった。「重複定義による音量調整」を(それをerrorとみなすかどうかはともかく)検出してくれるのは微妙に便利だったような気もするが、今回からそれができなくなった。まあ、適当に手元でscriptを書けば解決できるか。
日本語と英語以外は自信無いのと需要も分からないので、どうにもやる気が起きません……
気付かない部分の修正とかは投げてくれる人がいれば助かるんですが
私からすると第二言語を扱える方々はそれだけで超人です! 多言語対応appsの多くは未訳部分を英語のまま公開しているように見えます。
#IF–#ENDIFと#SWITCH–#ENDSWで階層を上げ下げしているらしき箇所が気になって仕方がないので、
Data
\xxx .Lang .xml と聞いて…… "View (V)" の部分を日本語化できるようにしたとき、中国語と韓国語は一切触らなかったことを思い出しました。
訳せないのはもちろん触ったら厄介なことを起こしそうで……
見てみたら項目すらつくられてませんでしたね。
英語xmlを基にして日本語xmlに翻訳されたNekokan氏だあ〜! そうですね、簡体字中国語xmlと韓国語xmlではこの箇所は言語files内に要素自体が存在せず、日本語表示から切り替えると「表示 (V)」のままになったりしますね。配下のview menu itemsは各言語に既に翻訳されているのですけれども。
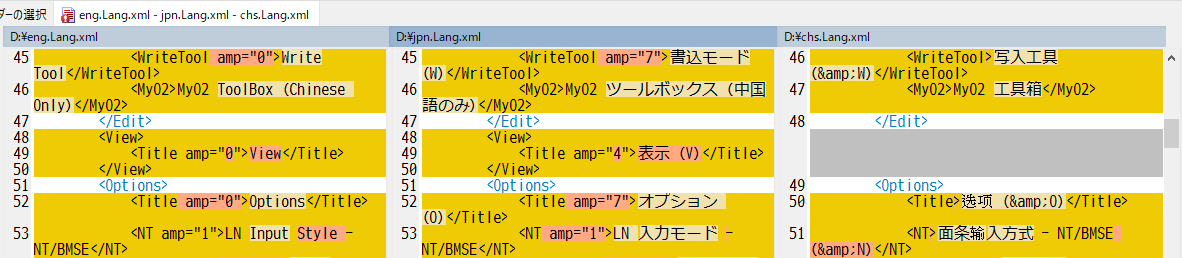
同様に
“Disable vertical moves”
Releasesの3.5.0の項、#LNTYPEは#LNMODEかな。あとtypo: (can't inport)
WAVを同名で上書き保存すると中身が消失する危ない感じのbugが修正された。あとCtrl+JでWAVの各種chunk情報が見られる機能は個人的に大助かり。私が今まで使っていたRIFF File Viewerよりも遥かに便利。ただsabamiso氏の\x94XなどのJSON invalidなescape文字列が出てきたりする。作品名をぱっと思い出せないが、Loop tagがめちゃくちゃ入れ子にされているWAV fileとかもどこかで見かけた記憶がある……
あとSemantic Versioningは廃止された模様。
#SKIP, #SKIP, run run run#TITLE skip
#BPM 130
#SWITCH 2
#SWITCH 2
#CASE 1
#00111:11
#SKIP
#CASE 2
#00113:33
#ENDSW
#SKIP
#CASE 1
#00115:55
#CASE 2
#00211:11「一つめの#SWITCH 2」から「二つめの#CASE 1」までの区間に、#SWITCH–#ENDSW」と「外側の#SWITCHに属する#SKIP」が存在する例。
一般的なprogramming言語では、このようなcodeは成立しないものと思われる。
11行目の#SKIPをcommented outすれば、このBMS codeはHDX#SWITCH–#ENDSWは丸ごと無視されるが、
nanasi#SKIPは機能するが、#SKIPは無視される。#CASE 1」にFALL-THROUGHしない。
私は書きかけの分岐parserを#SWITCH内容もv0.1.3では赤く染まるようだ。
こんばんは。
主要なBMS再生ソフトにおける、
#RANK 4(いわゆるVERY EASY判定)に対応していない場合のフォールバック先になる判定について、既に調べたことがありますでしょうか?https://
stellabms .xyz /u /st /644 上記リンクの
#RANK 4を使用した譜面の難易度議論で、「Lunatic Rave 2では #RANK 4のフォールバックが#RANK 2(いわゆるNORMAL判定)である」という興味深い情報を知って、もしかしたらhitkeyさんならこれに関連することを知ってたりするのかな~、と思って質問した次第です。
こんばんは。主要なBMS clientsについて私はよく知っているわけではなく、省略時の詳細は覚えていません。しかしながら私はWindows XPを使っていた時代に#RANKに限らず既定値全般について調査を進めてはいました。結果をどこにmemoしたか忘れてしまいましたが……
BMS Creator#RANK自体が書き出されず、判定は各clientsの定める既定値に委ねられます。当時のこの作成環境から、昔のBMSではそれなりにfallback判定が使われていた可能性があります。#RANK 4に関しても、しっかりした実装なら非対応の値を受け取ったとき既定値が適用されるのだろうと思います。
Bツ
(略) です。 スライス時のエラーすみません!プログラム側のミスでした。簡単にいうと「書き込み中のファイルの内容を読み込もうとした」ために発生したエラーです。修正したVer2.05を公開しました。
更新の自動チェック機能ありがたいです! Bit深度を変更してのWAV sliceも正常に動作することを確認しました。当方は細かい機能までは試しきれていませんが、既定の設定値を普通に適用するぶんには安定して動作しているんじゃないかなと思います。また何か問題があればご報告いたしますので〜
#RANDOM BMS list#OPTION command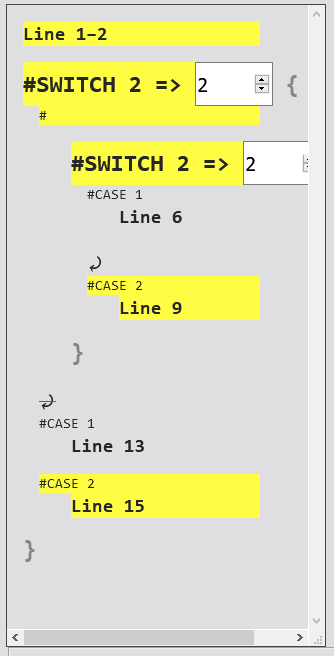{kind=link}